
Minor change, major results: LavinMQ streams hit 30% speed gain

We’ve just merged a simple yet powerful optimization that improves throughput: we no longer store redundant offset data for every message. Here’s how it worked before, what we changed, and what it means for your stream workloads.
To understand this optimization, let’s look at the historical approach. LavinMQ stores all stream messages in segments on disk, and it was within this structure that redundancy occurred. Before this optimization, we attached an x-stream-offset
header to every single message within every segment.
The problem was that this offset was entirely calculable. If you know the first message in a segment starts at offset 10,000, the second message is at 10,001, the third at 10,002, and so on. We were writing the same calculable information thousands of times per segment.
The solution: store once, calculate on demand
The fix was minimal and straightforward. Starting from LavinMQ v2.7.0, LavinMQ now stores the offset only for the first message in each segment. When a consumer reads messages, LavinMQ calculates offsets on the fly using simple math: segment’s starting offset plus the message’s position within that segment.
This approach eliminates redundant writes while keeping reads fast. The calculation is trivial compared with the I/O operations involved in reading messages from disk. You’re already paying for the disk read, so adding a simple addition costs essentially nothing.
Here’s what changed under the hood:
- At write-time: Only the first message in a segment gets offset metadata
- At read-time: Offsets are calculated using base offset + message position
- Storage impact: Each message is smaller, reducing disk I/O per write
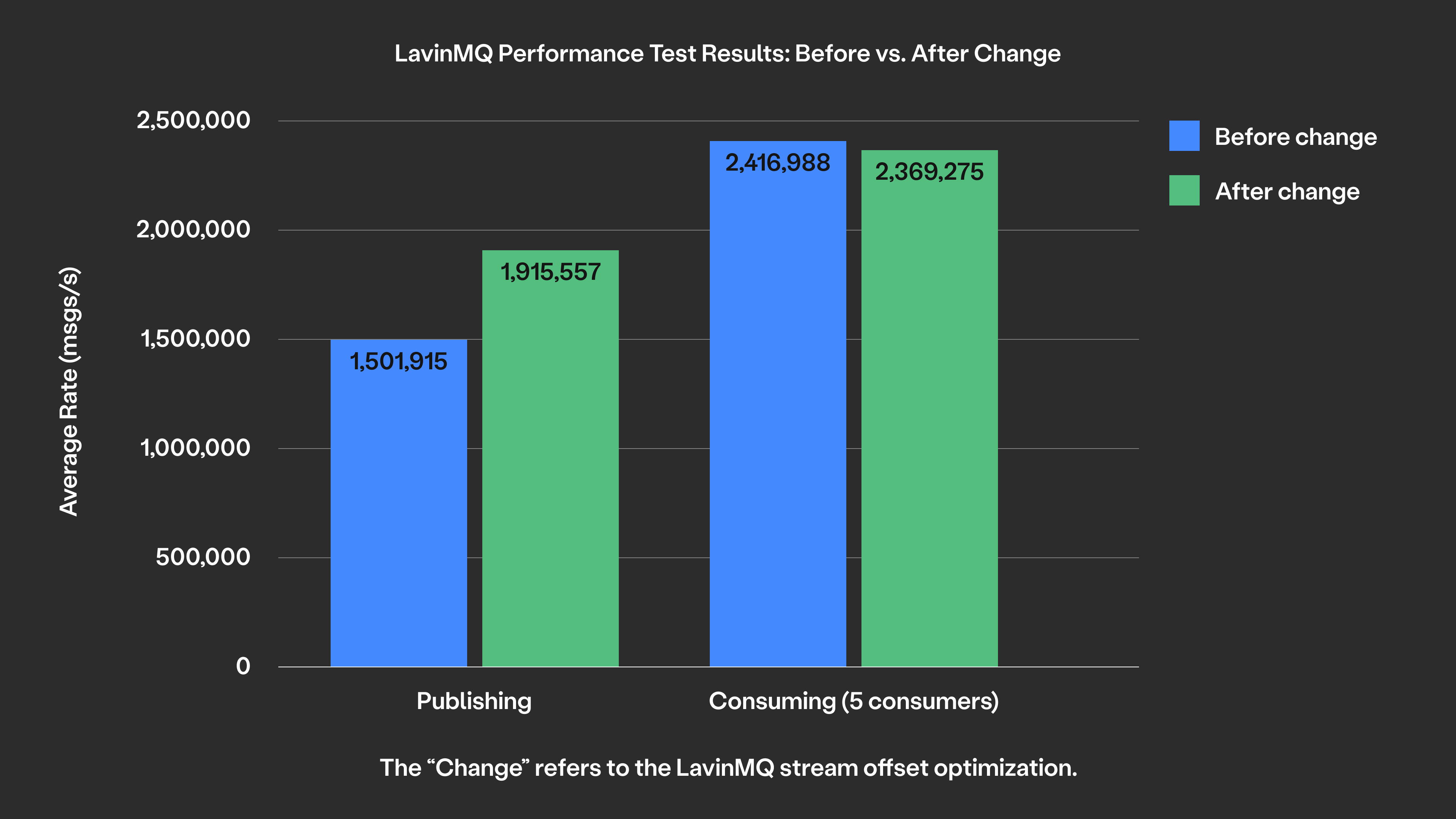
Real performance gains
The improvement is most noticeable with smaller messages because the overhead of redundant headers represents a larger percentage of the total message size. In our benchmarks, this optimization delivered roughly 30% faster write throughput with very small messages.
Read performance remained essentially unchanged. Calculating offsets on demand adds negligible overhead compared to disk I/O costs.
Reduced disk usage for long-lived streams
Beyond performance, this optimization also saves you disk space. Since we removed the unnecessary offset header, every message stored is now simply smaller. If you retain historical data for weeks or months, those small savings quickly add up. A stream with 10 million messages, for instance, stops storing 10 million redundant offset headers.
For short-lived streams or streams with retention policies that keep only recent messages, the disk savings will be minimal.
Backward compatibility and migration
If you’re running existing LavinMQ streams, they’ll continue working. The changed code handles segments written with the old format transparently. However, there’s one important compatibility note: messages written with this new version can’t be read by older LavinMQ versions.
Why this matters for your workloads
Stream performance often matters most when you’re handling high-volume, low-latency workloads. Think telemetry data, IoT sensor readings, or event logs where thousands of small messages flow through the system continuously.
By reducing the overhead of each write operation, we’ve made these workloads more efficient. You’ll see benefits in:
- Higher throughput: More messages per second with the same hardware
- Lower latency: Faster write operations mean less time waiting for acknowledgments
- Reduced resource usage: Less disk I/O frees up system resources for other operations
- Lower storage costs: Smaller message footprint means more efficient use of disk space
The optimization also compounds with scale. If you’re writing millions of messages per day, eliminating redundant data from each one adds up quickly.
Ready to try LavinMQ streams with this performance boost? https://www.cloudamqp.com/plans.html and start streaming messages in minutes.