
What is the Consistent Hash Exchange?
Consistent Hashing ensures that messages with the same identifier always go to the same queue, so they can be processed in the order they were sent.
The Consistent Hash Exchange uses a hashing process based on the producer’s routing key to achieve predictable and consistent routing. In this blog, we’ll dive into how it works and why it matters.
The Consistent Hash Exchange distributes messages using a hash function that maps input data (such as a ClientID orOrderID) to a numerical value. This ensures that messages are routed based on their hash.
Example: ClientID to Hash
ClientID: 40might map to Hash: 33ClientID: 145might map to Hash: 59
The broker defines the range of output values, ensuring a finite output hash space. For example, if a hash function outputs values between 0 and 100, there are 101 possible outputs.
The hash value dictates which queue receives the message, ensuring consistent routing for the same ClientID.
Bucket distribution
Consistent Hashing handles message routing, but you define how the hash space is distributed among queues. The hash space is divided into buckets, and each queue is assigned a certain number of buckets based on the routing key, usually a number(weight) of its bindings. A higher weight means more buckets, resulting in more messages for that queue.
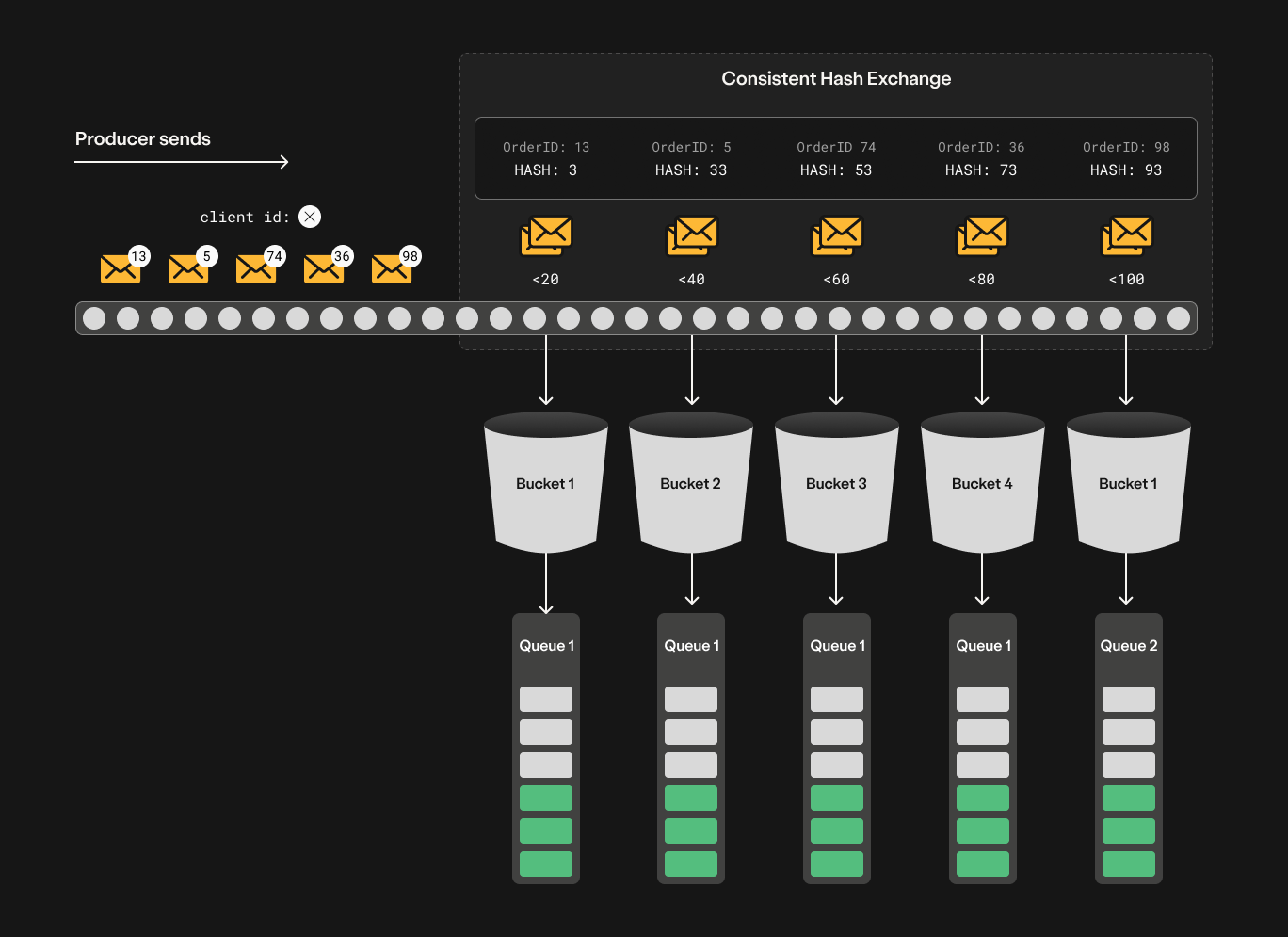
How would this play out in a real scenario? Suppose you’re running an e-commerce platform that routes customer orders (messages defined by the unique OrderIDs in the routing key). The OrderID determines which queue the message will be routed to based on its hash value.
Now, imagine you have two queues for handling order processing. The routing key on the binding defines how many buckets of the hash space each queue is responsible for.
It could look like this;
- Queue 1 (routing key on the binding = 4): This queue is responsible for four buckets.
- Queue 2 (routing key on the binding = 1): This queue is responsible for one bucket.
The hash space is divided into five total buckets (four assigned to queue_1, one to queue_2).
This means Queue 1 will receive 4× more messages than Queue 2.
Now, let’s assign specific hash values to each queue: In this example, the hash values are defined 0-100:
- Queue 1 handles 4 out of 5 buckets in the space (e.g., 0 ≤ Hash < 80).
- Queue 2 handles 1 out of 5 buckets in the space (e.g., 80 ≤ Hash < 100).
In reality, buckets are distributed around the hash ring, so the ranges are not necessarily contiguous, but each queue receives the correct proportion.
In this example, the hash space for the total of 5 buckets would be distributed as follows:
- Queue 1, Bucket 1: (0–20)
- Queue 1, Bucket 2: (20–40)
- Queue 1, Bucket 3:(40–60)
- Queue 1, Bucket 4: (60–80)
- Queue 2, Bucket 1: (80-100)
So what happens when orders from our e-commerce are sent to a system that uses consistent hash exchange?
- If an OrderID hashes to 14, it will go to Queue 1 and bucket 1.
- If the OrderID hashes to 33, it will go to Queue 1 and bucket 2
- If the OrderID hashes to 85, it will go to Queue 2 (since it falls within 80 to 100).
As seen in the illustration, orders will be distributed the way we wanted, but we have ensured that all orders with the same OrderID end up in the same queue in logical order.
Flexibility of the Consistent Hash Exchange
What happens when we change the number of queues? Adding or removing queues redistributes the hash space. This may cause some keys to be reassigned to different queues, but consistent hashing minimizes how many keys move. As long as the set of queues remains stable, messages with the same key always go to the same queue in order. New queues get proportionally reallocated buckets, ensuring an even distribution, while removing a queue and redistributing its space to the remaining ones.
The following example demonstrates the scenario of when a new queue with a binding routing key (weight) of 1 is added to the system. Now we have six buckets in total instead of five. Buckets are redistributed across queues. For example, Queue 1 could now handle 4 out of 6 buckets, Queue 2 one bucket, and Queue 3 one bucket. In practice, the buckets are spread around the hash ring, but for simplicity we can illustrate them as ranges.
Summary
The Consistent Hash Exchange ensures predictable and consistent routing using a hash function based on the producer’s routing key, like ClientID or OrderID. This approach maintains causal order by routing messages with the same identifier to the same queue. The hash space can be divided across multiple queues, with each queue assigned a specific number of buckets based on its routing key.
This also enables efficient load balancing, since you can control how much of the hash space each queue handles — helping distribute the workload as evenly as you need.
Read more about how to set up and configure a consistent hash exchange.
Lovisa Johansson