
Why we run our AI agent on a message queue

At 84codes we’ve been building messaging infrastructure for well over a decade. A lot has changed in that time, especially the last couple of years with the rise of agentic systems, but the message broker still stands strong. Take our internal AI agent 84bot as an example:
84bot answers questions in Slack. When an engineer asks something, it has access to live data from a dozen internal systems (metrics, logs, error tracking, customer support tickets, billing, cluster state, the engineering handbook, etc.), stitches that together, and replies in thread.
84bot also:
- Triages on-call alerts with a root cause analysis and resolution plan.
- Fires off coding agents that open draft pull requests directly from Slack.
- Runs recurring checks anyone on the team can set up from Slack, and posts back once the job triggers.
- Flags drift in documentation and suggests corrections.
- Autoscales itself.
Under the hood, the Anthropic SDK runs the model loop. LavinMQ handles everything around it: durability, scheduling, fanout, backpressure.
Almost every feature 84bot grew into came from something a message broker already gave us for free. Here’s how it became the runtime for our AI agent.
Start with the queue
The naive way to build an AI agent is synchronous and in-process. You follow the SDK quickstart. The model thinks, calls a tool, waits for the result, thinks again, all inside one request handler. 84bot’s first version was that exact shape, on a serverless platform. It had two problems.
Durability. If the function fails there is no reply mechanism unless you build that yourself. The user simply won’t get a reply.
Bursts. When several people asked at once, requests piled up and the bot got slow. There was no buffer between the webhook and the model, no easy way to scale out.
The fix was to put a broker in the middle.
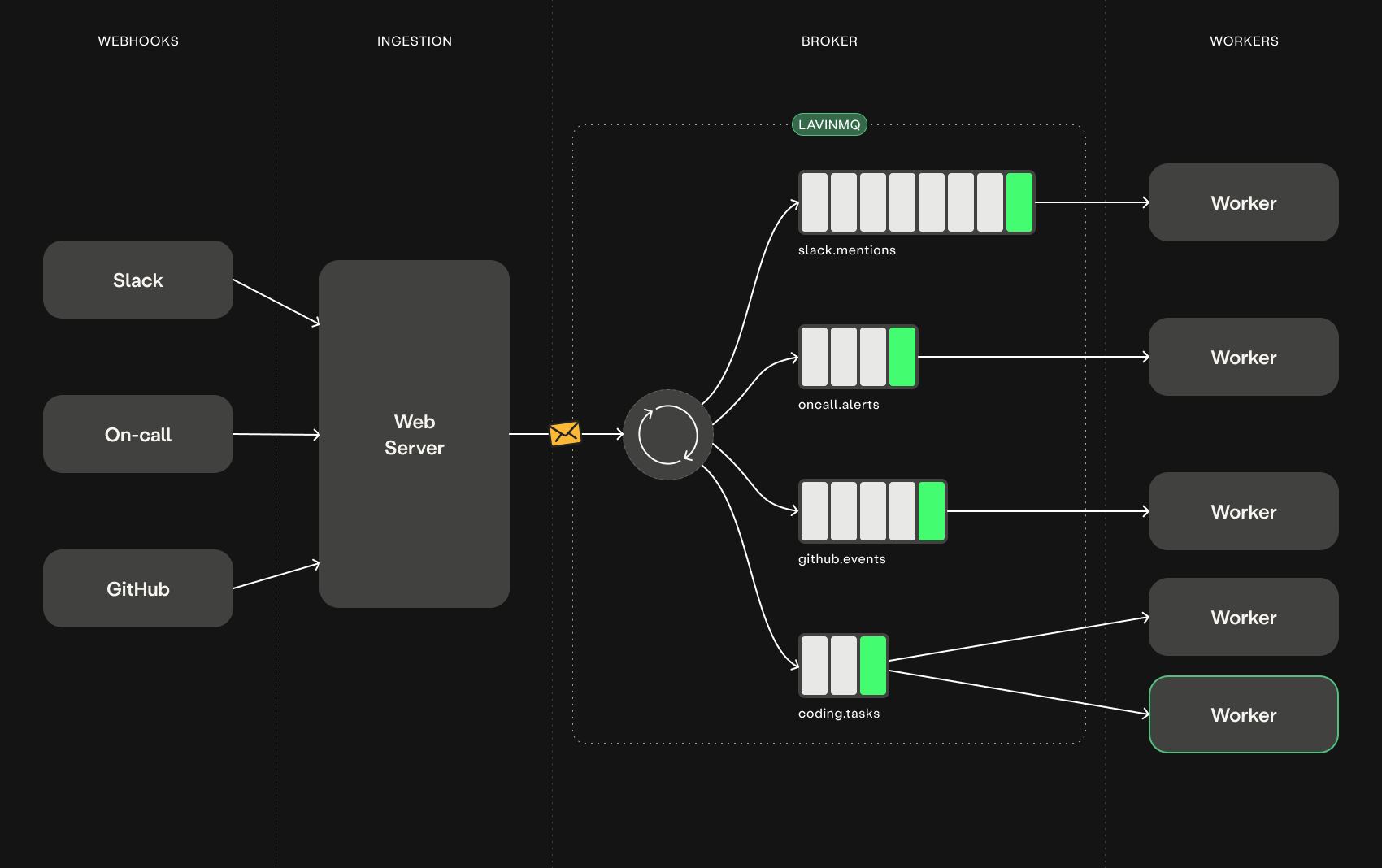
The architecture split into three parts:
- Ingestion. A web server that does nothing but verify webhook signatures and publish a message to LavinMQ. Replies to Slack in milliseconds.
- Broker. LavinMQ holds messages durably. If no worker is available, messages wait. If a worker dies mid-task, the unacknowledged message goes back on the queue automatically.
- Workers. Pull from the queue and run the agent. Each one is long-running and processes one message at a time.
That split is the foundation everything else is built on. Crashes don’t lose work. Bursts don’t drop messages. Each side fails, deploys, and scales independently. You get that shape almost for free once the broker sits in the middle.
Different traffic, different queues
Once you have a queue, two queues cost you nothing. Then three. Then five.
84bot has a queue for Slack mentions, one for on-call alerts, one for GitHub events, and one for long-running coding tasks. Each gets its own worker process, its own prefetch setting, its own concurrency limit.
Find out tomorrow you need message priority? Already built in. We haven’t needed it yet, but the day we do it’s a header on the message, not a new system.
The same shape lets us scale horizontally. Add a worker, it pulls from the same queue. No load balancer, no sticky sessions, no consistent hashing. If a work queue is building up we just spin up another consumer, and when the queue goes silent we scale to zero.
The queue holds work while workers autoscale to demand, so an idle agent costs nothing and a spike doesn’t cause much latency.
Fanout: one event, many agents
We also ingest GitHub events to generate or update docs, classify the change for the changelog, and sometimes hand it to a coding agent for follow-up.
A synchronous design would chain those into one big handler. With a broker, the GitHub webhook publishes to a fanout exchange and three independent consumers listen, each running its own agent prompt with its own tools. They run in parallel, fail in isolation, and we can add a fourth consumer without touching the existing three.
This is the AMQP feature most agent frameworks rebuild from scratch as “subagents” or “parallel orchestrators.” Brokers have done it for 20 years. We just pointed our agents at it.
Scheduled messages: agents that wake themselves up
Our bot isn’t only reactive. We want it to check things on a schedule, follow up on stalled threads, remind us about incidents that haven’t been postmortemed.
Delayed messages are the primitive. We publish a message with a delay header and the broker holds it. When the timer expires, the message lands on a queue and a worker picks it up. The agent code doesn’t care that the trigger came from a clock instead of a human.
Our scheduled-monitors feature is built entirely on this. A user tells 84bot in Slack: “check the staging cluster every hour and tell me if connections drop below 100.” The bot publishes a delayed message and goes back to sleep. An hour later the message arrives, the agent runs, and if the condition fires it posts in the original thread, then reschedules itself for the next run. No cron daemon, no scheduler service, no extra moving part. The broker is the scheduler.
Scheduling an agent run is just publishing a message.
What you stop writing
Each of these primitives replaces something most agent frameworks ship as code: retry wrappers, circuit breakers, workflow engines, subagent orchestrators, cron schedulers, priority queues.
After we leaned into AMQP, we could delete all retry logic from our Claude tool loop. If a tool call fails, we nack the message and the broker redelivers it. Poison detection catches the case where retry will never help. Durable queues persist messages across broker restarts. There’s nothing left for application-level retry to do.
Many frameworks reinvent this machinery in userspace. Once your agent runs on a broker, most of it moves down to infrastructure, where it’s simpler and more battle-tested.
What you take away
A durable message broker covers most of what an AI agent actually needs at runtime: crash recovery, backpressure, fanout to parallel agents, scheduled wake-ups, and priority traffic. Each of those is a primitive your broker already ships, not code your team has to write or a framework you have to adopt. Build on the broker first; add a framework only if something genuinely doesn’t fit.
Why LavinMQ
We’re a message queue company, so yes, there’s some dogfooding here, maybe even a bit of infrastructure in search of a problem, but the fit is genuine. LavinMQ is small and fast, supports durable queues, delayed messages, fanout exchanges, and priority queues out of the box. An AI agent’s traffic pattern: receive work, process work, acknowledge work, sometimes schedule the next round. That’s the workload message brokers were built for. We wrote LavinMQ because this is the shape of system we keep building, before agents and now with them.
If you’re building an AI agent that real people will depend on, put it behind a queue. Try LavinMQ for free on CloudAMQP and copy the pattern.
Anders Bälter
CTO