
How queues power the world's systems

If you’ve ever bought something online, uploaded a photo, or received an email notification, you’ve most likely interacted with a queue. Queues quietly connect services, handle load, and keep systems reliable, even when traffic peaks.
What exactly is a queue?
A queue is a place where messages wait for their turn, where each message represents a unit of work or data that one service sends to another. A queue works like a line at a coffee shop: requests come in, wait a bit, and are processed in order. Most queues follow the First-In, First-Out (FIFO) principle: the first message to enter is the first to be processed. It’s simple, predictable, and a big part of why queues work so well under pressure.
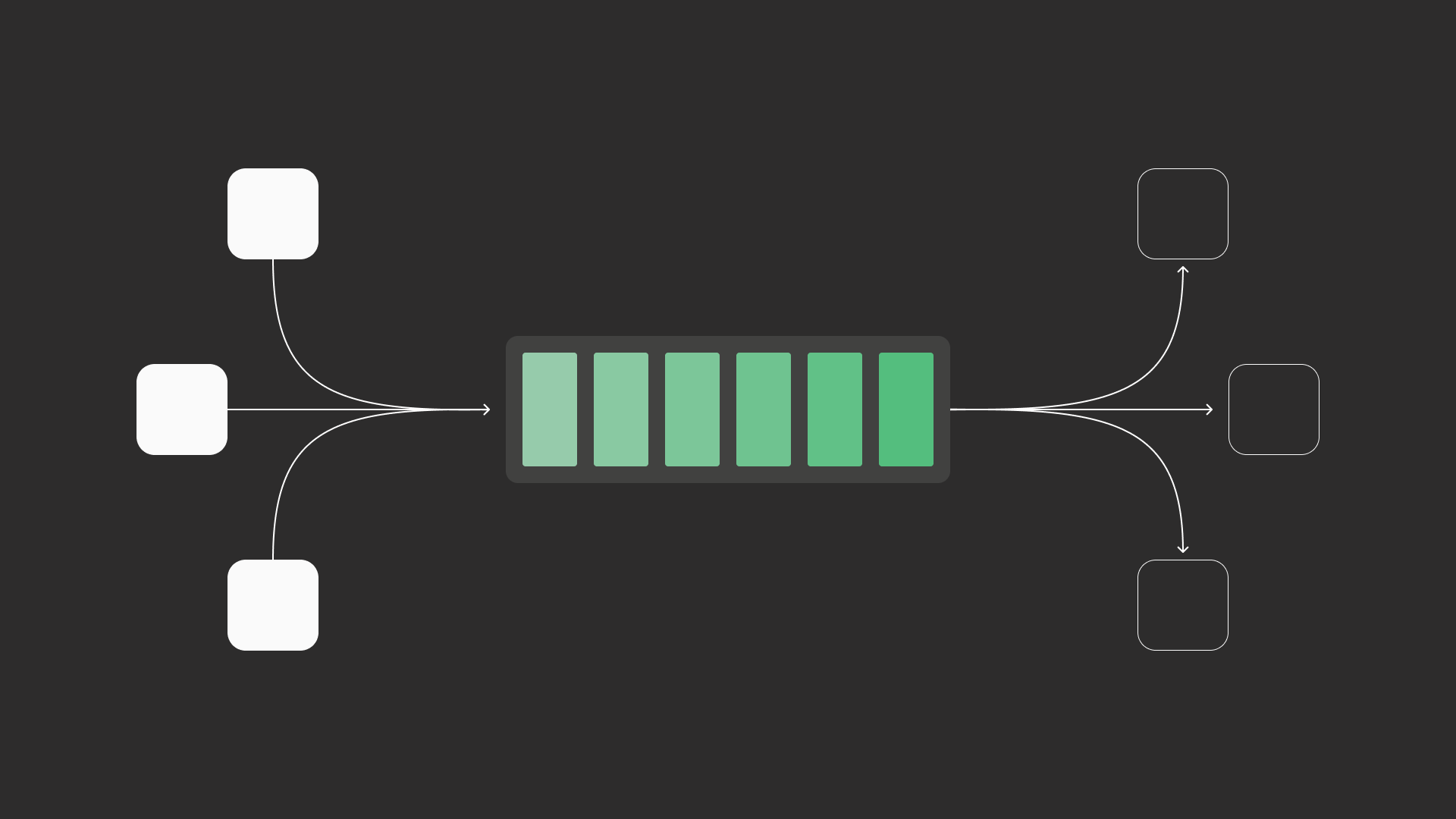 Queues deliver work to consumers and remove messages once processed.
Queues deliver work to consumers and remove messages once processed.
These queues aren’t just code snippets.
Modern queueing services such as LavinMQ, RabbitMQ take this concept way further (and others like Kafka, ActiveMQ, and Amazon SQS do as well). They are built to handle thousands of messages per second, support multiple producers (sending data) and consumers (processing data), provide automatic retries, and offer high fault tolerance.
Use case 1: Handling traffic spikes.
You’ve probably walked through a door, and that works fine as long as a thousand people aren’t trying to do it at the same time. That bottleneck is exactly the kind of problem queues are designed to solve in software. This is where LavinMQ’s slogan speaks for itself: “A message broker built for peaks.” One of the most important roles of a queue is to buffer traffic spikes, preventing services from crashing under pressure.
The problem: When capacity is exceeded
Imagine running a server that receives 2,000 orders per second, but your database or worker can only handle 200 writes per second. If you try to process all requests directly, you risk:
- The receiving service (like a database or API) can crash from overload.
- Dropping customer requests, leading to lost revenue and poor user experience.
The queue solution: Buffer data
By introducing a queue between the incoming traffic and the worker, you create a buffer:
- The queue absorbs and temporarily stores all incoming requests.
- Your consumers process them at a steady, sustainable rate of 300 per second.
This setup achieves decoupling. Producers can publish as fast as data arrives, and consumers process it at a steady rate. Even during a 10x traffic spike, the queue buffers the load and processes it once capacity allows.
Use case 2: Handling time-consuming tasks (making APIs asynchronous)
Queues are perfect for making APIs asynchronous, especially for long-running or resource-intensive operations.
The problem: Generating a large report
Imagine a business intelligence platform where a user requests a custom report covering a year’s worth of data.
If the API tries to generate this report synchronously (immediately), several issues arise:
- The request could take 30 seconds or more to aggregate all the data.
- The user’s browser or mobile app would display a loading spinner for a long time, often leading to a timeout error or a poor user experience.
- The server handling the API request stays busy for the entire duration, preventing it from serving other requests.
The queue solution: The asynchronous flow
Instead of blocking the user, we use a queue to process the task in the background. The API immediately adds a message (with user/report details) to the queue and returns an instant response (“Report generation started”) to the user. A separate, dedicated background worker later receives this message from the queue and performs the heavy work of generating the report. When it’s done, the system notifies the user by email or push notification.
This pattern improves the user experience and system reliability by ensuring the user is never blocked by a long task. It’s a standard approach for workloads like sending emails, processing payments, or generating large reports — and the same principle applies to many other asynchronous workflows.
Use case 3: Event fanouts with microservices.
In large-scale architectures, queues enable fanouts where multiple microservices need to react to the same event.
The problem: Synchronous and coupled actions
When a single event, like a “New user sign-up”, needs to trigger several independent actions (for example, sending an email, updating analytics, notifying a recommendation service), an approach is to have the sign-up service synchronously call all the others.
This approach creates tight coupling: the success of the sign-up service depends on the immediate availability of all the other services. The system is fragile because if a downstream service fails, the entire user sign-up process might be negatively affected or slowed.
The queue solution: Decoupling with Publish-Subscribe
Instead of a single system synchronously calling all others, the event is published to a topic via a queueing system. This event then fans out, sending a copy of the message to a dedicated queue for every microservice that needs to react (Email Service, Analytics Service, CRM System, etc.).
Each service handles the request at its own pace, independently of the others. This achieves pure decoupling, allowing large-scale systems to handle millions of asynchronous events reliably and without cross-service dependencies.
Use case 4: Ensuring reliability with retries
Queues provide fault tolerance by automatically handling failures and retries, ensuring that no task is permanently lost due to a temporary glitch.
The problem: A temporary worker’s failure
Imagine a worker service processing a message, such as a payment, and it suddenly crashes due to a temporary network issue or a more permanent code bug. Without a safety net, the message could be lost, leading to data inconsistencies or failed transactions. The system must quickly determine whether the failure was a one-time glitch or a recurring, permanent problem.
The queue solution: Visibility timers and automatic retries
The system manages message failures in a two-stage process. First, to handle temporary problems, the message enters a visibility timeout when a worker receives it, hiding it from other workers. If the worker crashes, the queue automatically makes the message visible again for a new, healthy worker to retry. This handles common transient errors.
If, however, a message keeps failing repeatedly (due to a bug or a malformed payload), it can reach the maximum retry count (for example, five attempts). At that point, it’s moved to a dead-letter queue (DLQ) for manual review.
From this dead letter queue, an on-call engineer can easily inspect the message. They can diagnose the bug and manually correct the situation. This ensures temporary problems are automatically fixed, while serious bugs are isolated for human review, keeping the system stable.
Use case 5: Aggregating sensor data from many IoT devices
Queues and streams help systems handle massive amounts of real-time data from countless sources, such as smart sensors and monitoring tools.
The problem: Managing thousands of IoT devices
Consider a smart city project that involves 10,000 sensors simultaneously reporting temperature, traffic, snow status, and air quality, every five seconds. This creates a constant stream of data (up to 2,000 messages per second) that needs to be collected, aggregated, and analyzed.
- Directly connecting all 10,000 devices to a processing service or broker could overwhelm network connections and application servers.
- The data arrives too quickly for a single centralized database to handle initial ingestion.
The queue solution: Separating ingestion and analysis
By using a streaming or queueing architecture, you can decouple data ingestion from the slower, more complex analysis. Here’s how it works:
- Devices use a lightweight protocol such as MQTT to publish data to a queue or stream.
- The events are then fanned out to multiple specialized worker services (consumers).
- One consumer can perform real-time anomaly detection for immediate alerts, while another aggregates data for hourly batch analysis.
LavinMQ is designed to handle hundreds of thousands of concurrent connections with minimal overhead. It’s ideal for large-scale IoT environments. Thousands of devices can stay connected simultaneously, each publishing data without overloading the broker or the network.
Beyond queues: Streams, priority, and protocol flexibility
While traditional queueing focuses on temporarily storing messages until they’re delivered, like sending a physical package, modern systems also support Streams. These offer streaming capabilities that store an immutable sequence of events, meaning the data stays in the stream even after it’s read.
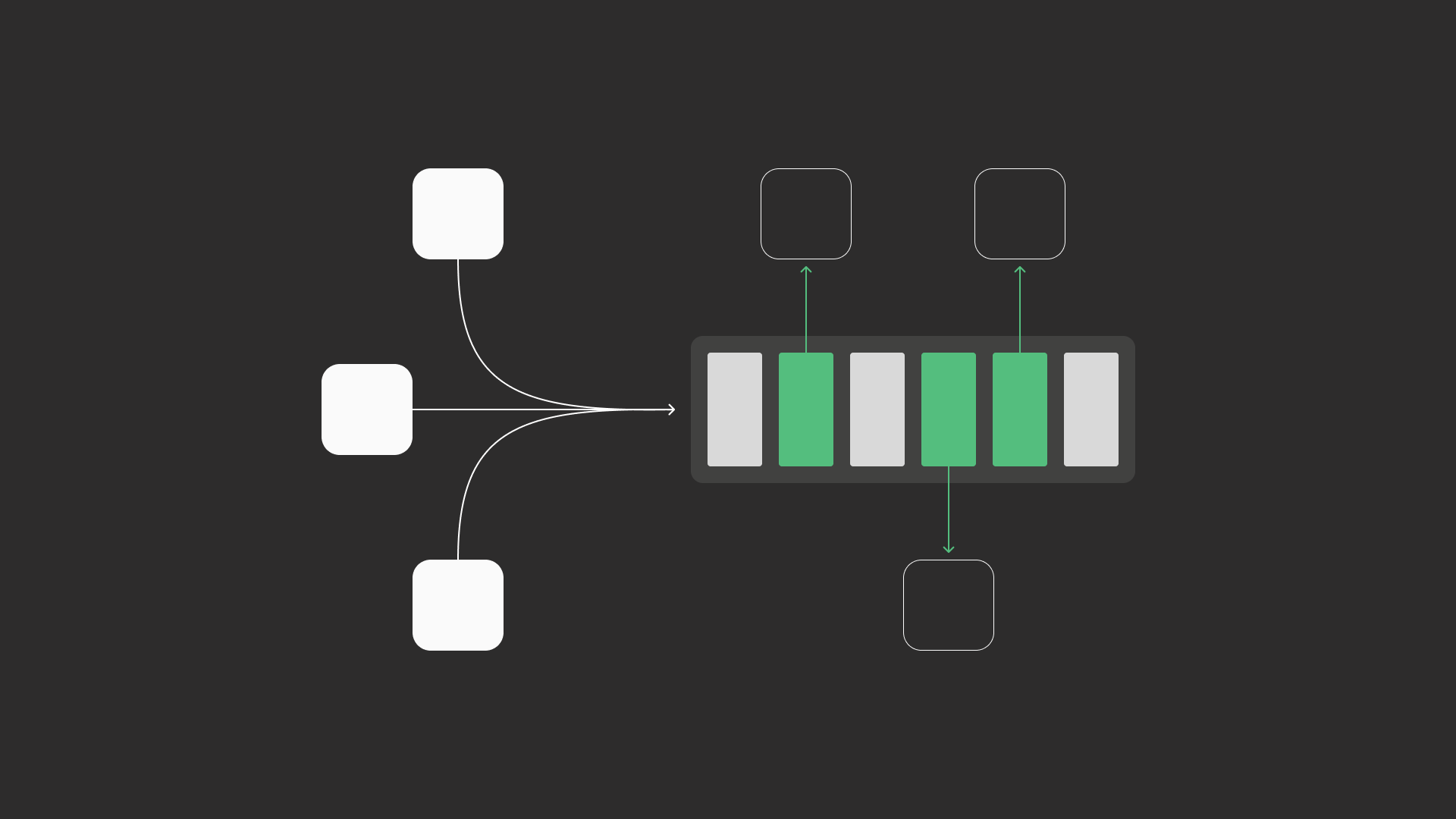 Streams record events in order and let multiple consumers read independently. Consumers track their own position (offset)
Streams record events in order and let multiple consumers read independently. Consumers track their own position (offset)
This approach is ideal for logging and real-time analytics, as multiple systems can independently process the same data. For critical workloads, priority queues make sure important messages skip the line for immediate attention. Many brokers are also multi-protocol, capable of handling various connection types such as the lightweight MQTT protocol, which is perfect for connecting thousands of IoT sensors and devices.
The queue use cases are endless
From handling communication and managing traffic peaks to enabling asynchronous APIs and supporting IoT and event-driven architectures, queues are a foundational part of modern systems. They keep data flowing across industries — from manufacturing lines and financial transactions to healthcare platforms and logistics networks.
Whether you’re building a small microservice architecture or a large distributed platform, a reliable queue service (message broker) helps keep everything running efficiently and resiliently.
Curious to try queues in practice? You can spin up a LavinMQ instance in seconds via CloudAMQP and start experimenting for free. It’s also simple to install and run locally if you prefer to explore on your own machine.
Lovisa Johansson